

 論壇執行長
論壇執行長















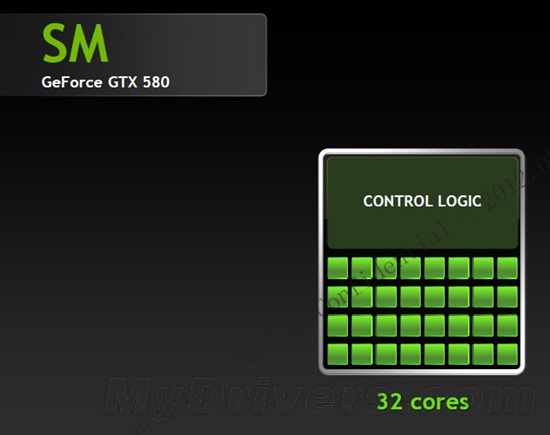
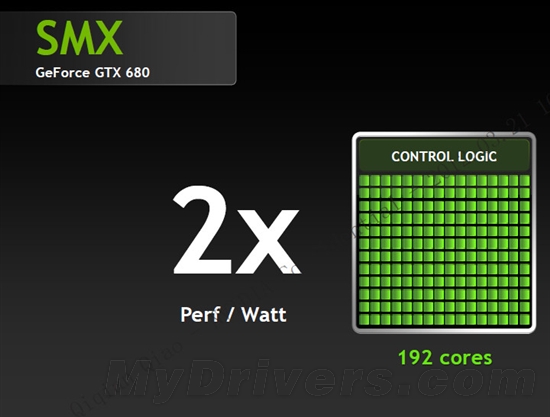


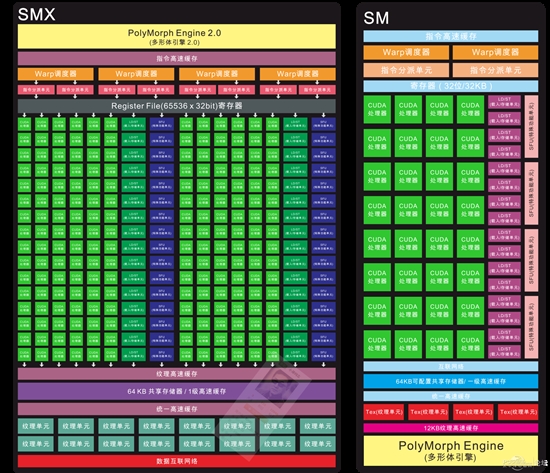
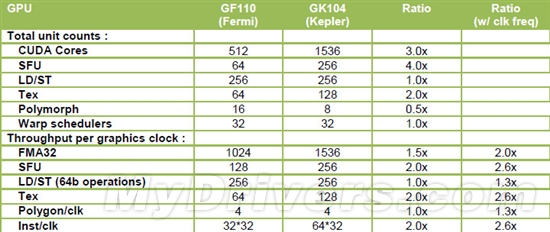







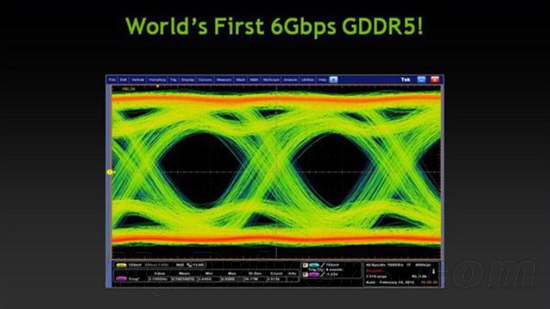
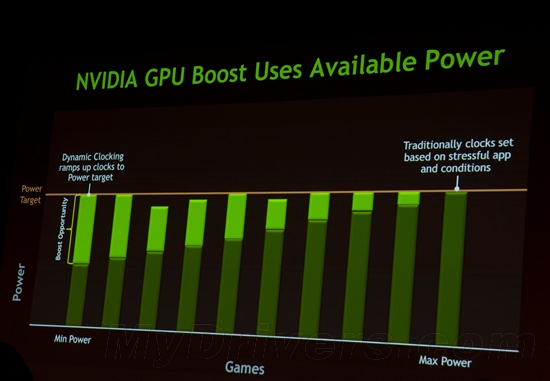



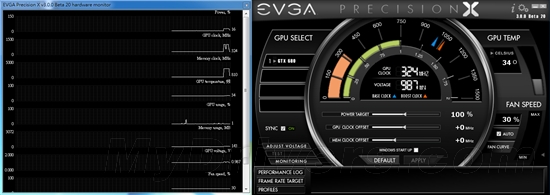
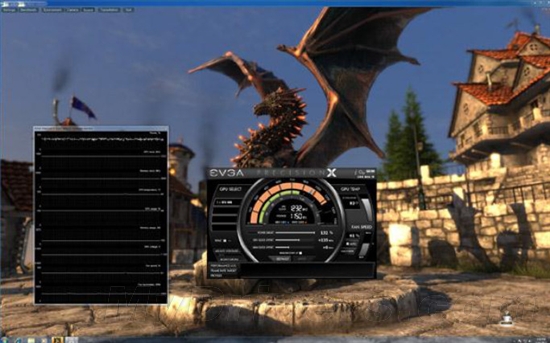

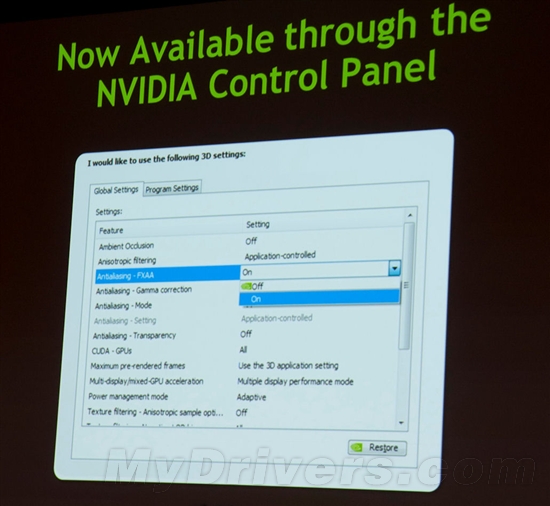




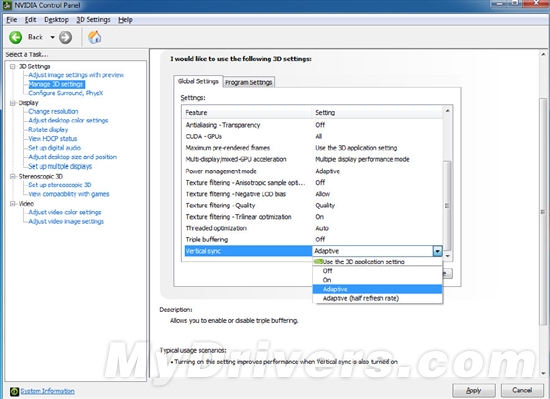





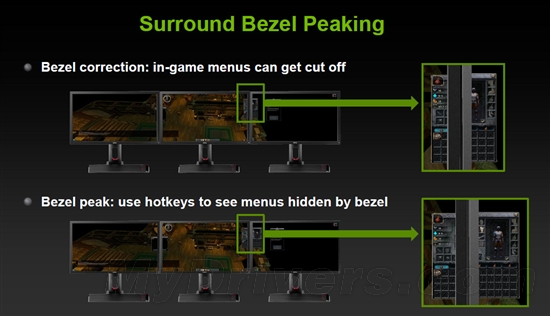






















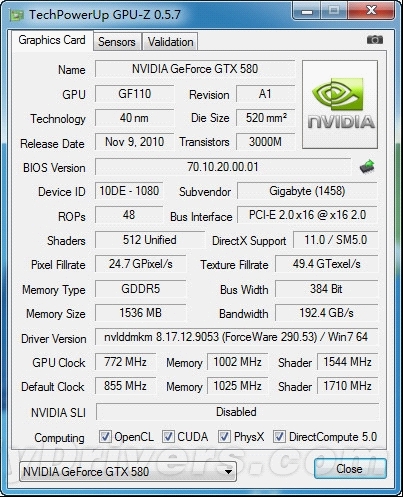


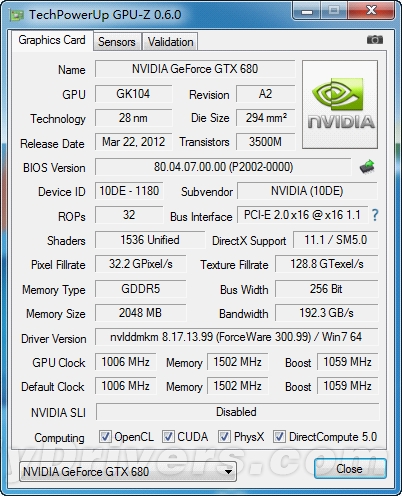





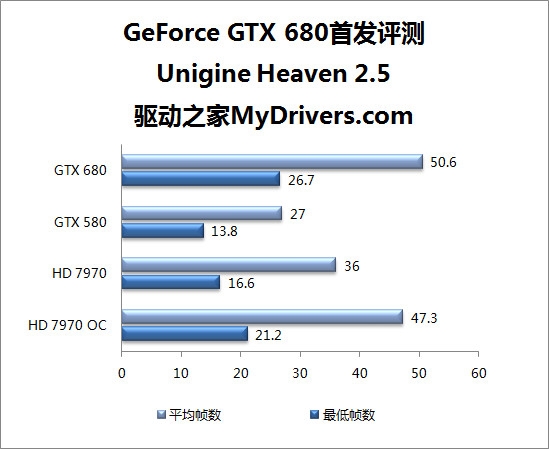



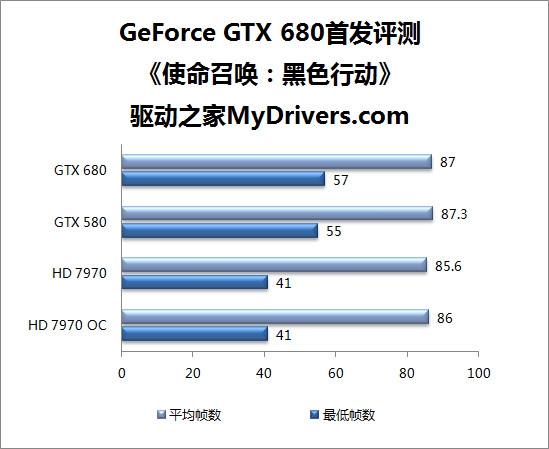



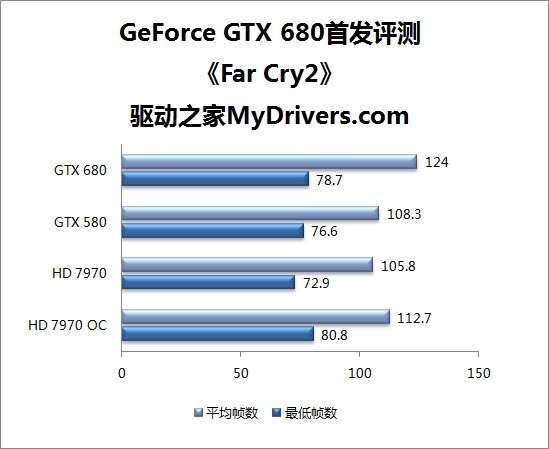





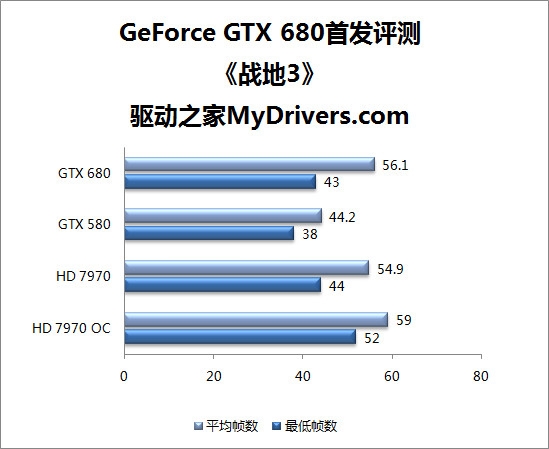

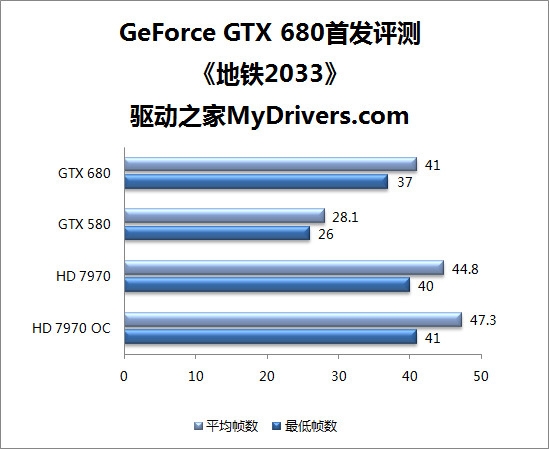

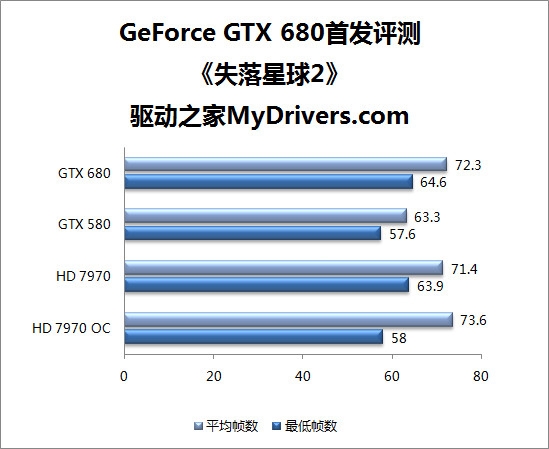






 --共勉之--
--共勉之--


|
»
您尚未 登入
| 註冊
| 說明
| 娛樂中心
| 點歌
| 聊天留言
|
最新
| 精華
| 論壇
| 資訊
| 首頁
| 影音模式
| |
|
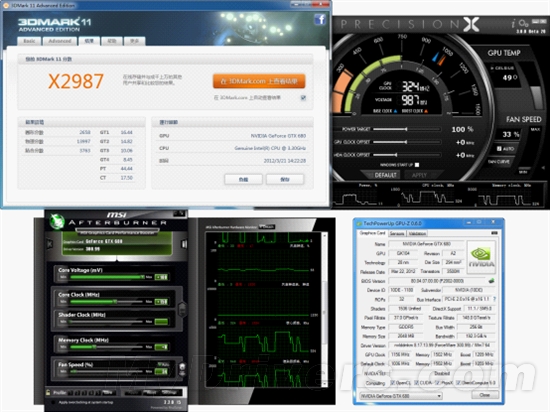
| --> 本頁主題: 【資訊】開普勒架構全解析 GeForce GTX 680震撼首測 | 加為IE收藏 | 收藏主題 | 上一主題 | 下一主題 | 可列印版本 |
| |||||||||||||||||||||||||||||||||||||||||||||
 熊蓋站 ->
硬體資訊
熊蓋站 ->
硬體資訊 |



|
v 最新文章 熊蓋站為自由討論論壇,所有個人行為或言論不代表本站立場。文章內容如有涉及侵權請聯絡我們,將立即刪除相關文章資料 v 精華文章